How to Install Hadoop on Windows 10 Using Vmware

By: Jeff Levy
Hadoop Distributed File System Overview
This step-by-step tutorial will walk you through how to install Hadoop on a Linux Virtual Machine on Windows 10. Even though you can install Hadoop directly on Windows, I am opting to install Hadoop on Linux because Hadoop was created on Linux and its routines are native to the Linux platform.
Prerequisites
Apache recommends that a test cluster have the following minimum specifications:
- 2 CPU Cores
- 8 GB RAM
- 30 GB Hard Drive Space
Step 1: Setting up the Virtual Machine
-
- Download and install the Oracle Virtual Box (Virtual Machine host)
- Download the Linux VM image. There is no need to install it yet, just have it downloaded. Take note of the download location of the iso file, as you will need it in a later step for installation.
- This tutorial will be using Ubuntu 18.04.2 LTS. You may choose to use another Linux platform such as RedHat, however, the commands and screenshots used in this tutorial will be relevant to the Ubuntu platform.
- The Ubuntu iso can be found here.
- Now, open up the Oracle VM VirtualBox Manager and select Machine [wp-svg-icons icon="arrow-right-2″ wrap="i"] New.
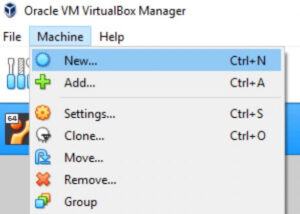
-
- Choose a Name and Location for your Virtual Machine. Then select the Type as 'Linux' and the version as Ubuntu (64-bit). Select 'Next' to go to the next dialogue.
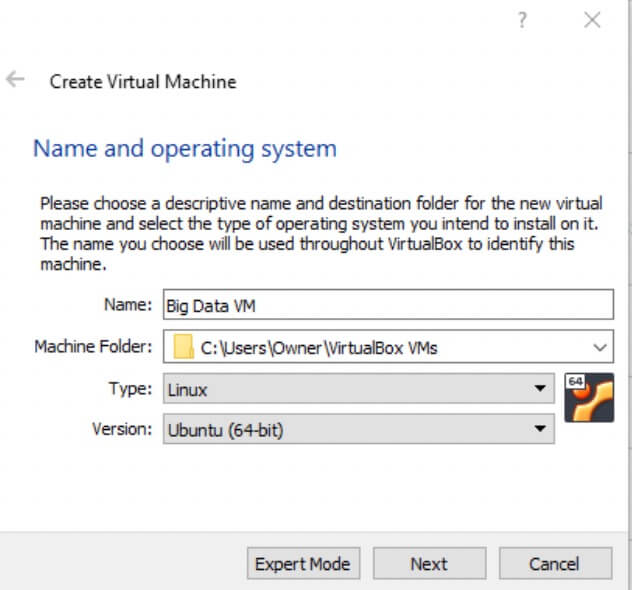
-
- Select the appropriate memory size for your Virtual Machine. Be mindful of the minimum specs outlined in the prerequisite section of this article. Click Next to go onto the next dialogue.
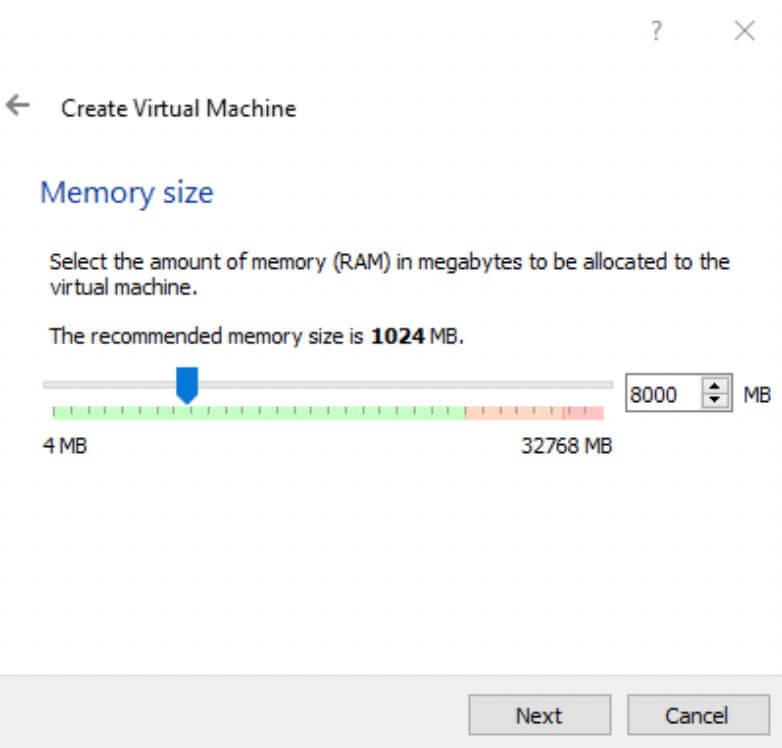
-
- Choose the default, which is 'Create a virtual hard disk now '. Click the 'Create' button.

-
- Choose the VDI Hard Disk file type and Click 'Next'.
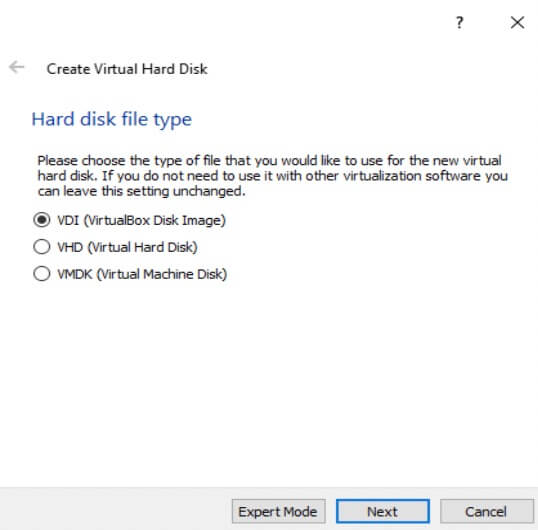
-
- Choose Dynamically allocated and Select 'Next'.
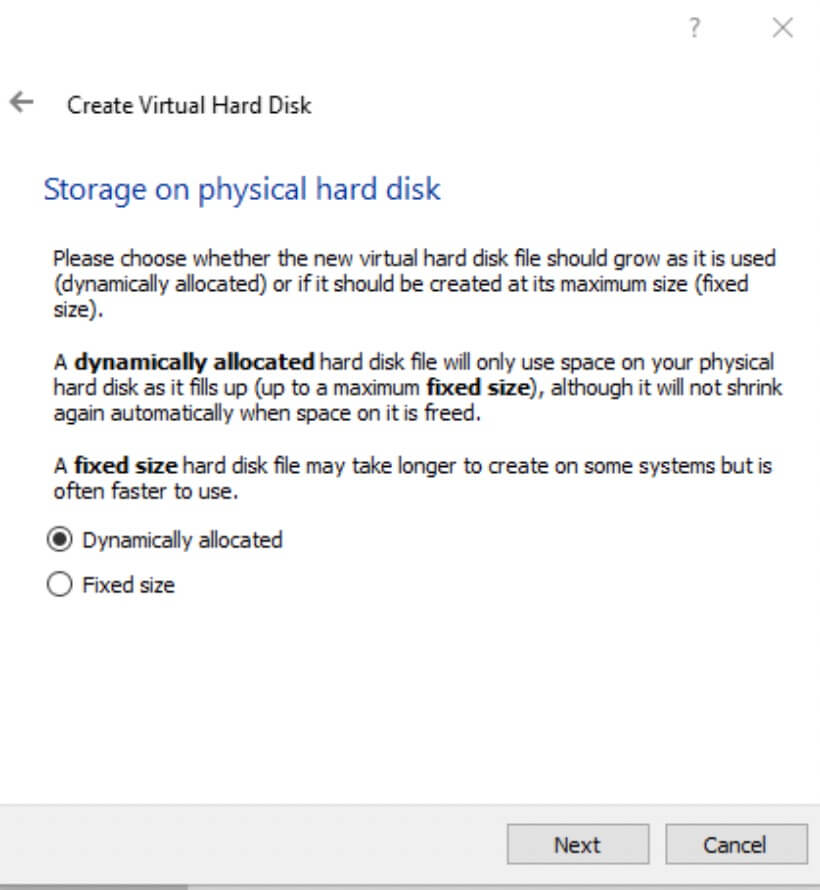
-
- Choose the Hard drive space reserved by the Virtual Machine and hit 'Create'.
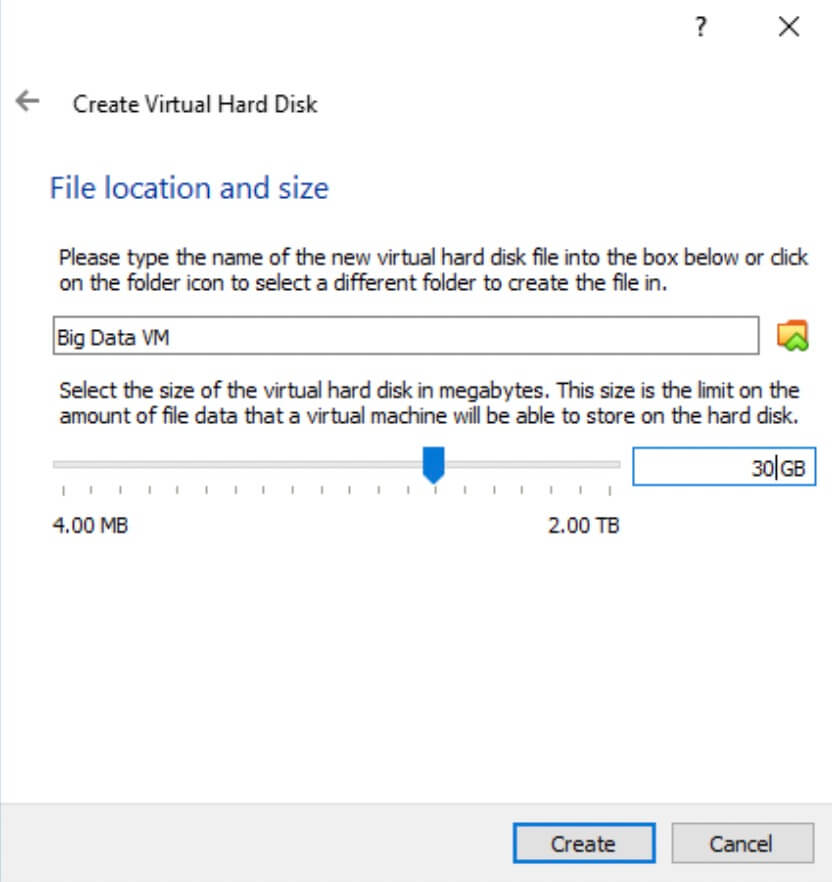
-
- At this point, your VM should be created! Now go back to the Oracle VM VirtualBox Manager and start the Virtual Machine. You can start your machine by right clicking your new instance choosing Start [wp-svg-icons icon="arrow-right-2″ wrap="i"] Normal Start.
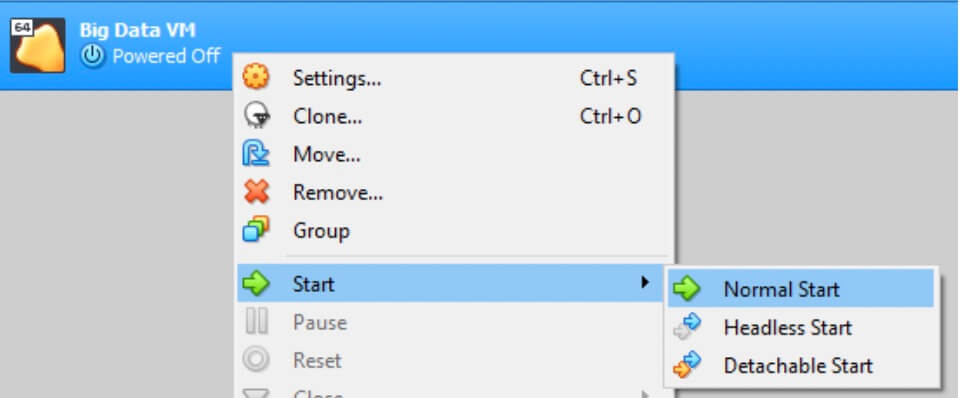
- After selecting Start, you will be prompted to add a Start-up disk. You will need to navigate on your file system to where you saved your Ubuntu ISO file.
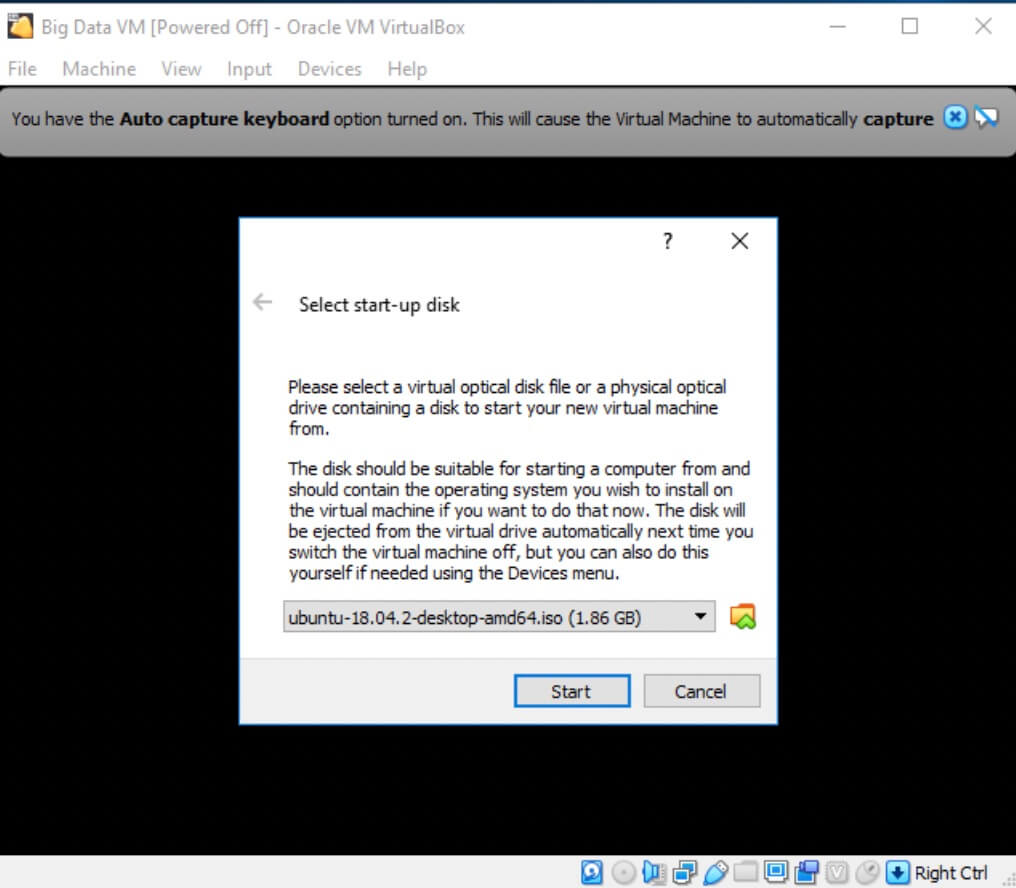
At this point, you will be taken to an Ubuntu installation screen. The process is straightforward and should be self-explanatory. The installation process will only take a few minutes. We're getting close to starting up our Hadoop instance!
Step 2: Setup Hadoop
Prerequisite Installations
Next, it's necessary to first install some prerequisite software. Once logged into your Linux VM, simply run the following commands in Linux Terminal Window to install the software.
-
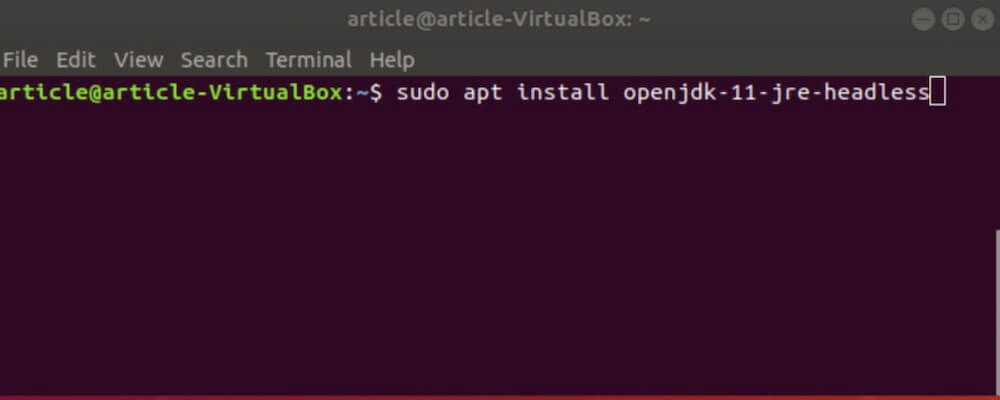
- JAVA: Terminal Command:
| $ sudo apt install openjdk - 11 - jre - headless |
-
- ssh: Terminal Command:
| $ sudo apt - get install ssh |
-
- pdsh: Terminal Command:
| $ sudo apt - get install pdsh |
Download and Unpack Hadoop
Now let's download and unpack Hadoop.
-
- To download Hadoop, enter the following command in the terminal window:
| $ wget http : //www.gtlib.gatech.edu/pub/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz |
-
- To unpack Hadoop, enter the following commands in the terminal window:
| $ tar - xvf hadoop - 3.3.0.tar.gz $ mv hadoop - 3.3.0 hadoop $ sudo mv hadoop / / usr / share / $ export HADOOP_HOME = / usr / share / hadoop |
Setting the JAVA_HOME Environment Variable
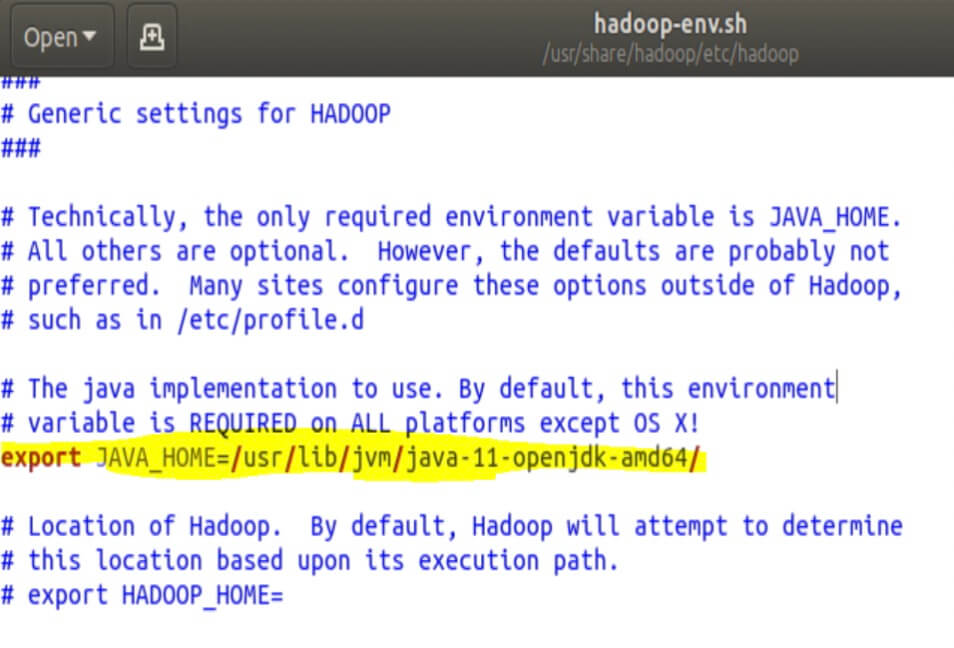
Navigate to the 'etc/hadoop/hadoop-env.sh' file and open it up in a text editor. Find the 'export JAVA_HOME' statement and replace it with the following line:
| export JAVA_HOME = / usr / lib / jvm / java - 11 - openjdk - amd64 / |
It should look like the picture below.
Standalone Operation
The first mode we will be looking at is Local (Standalone) Mode. This method allows you to run a single JAVA process in non-distributed mode on your local instance. It is not run by any Hadoop Daemons or services.
-
- Navigate to your Hadoop Directory by entering the following command in the terminal window:
-
- Next, run the following command:
The output should look similar to the following:
-
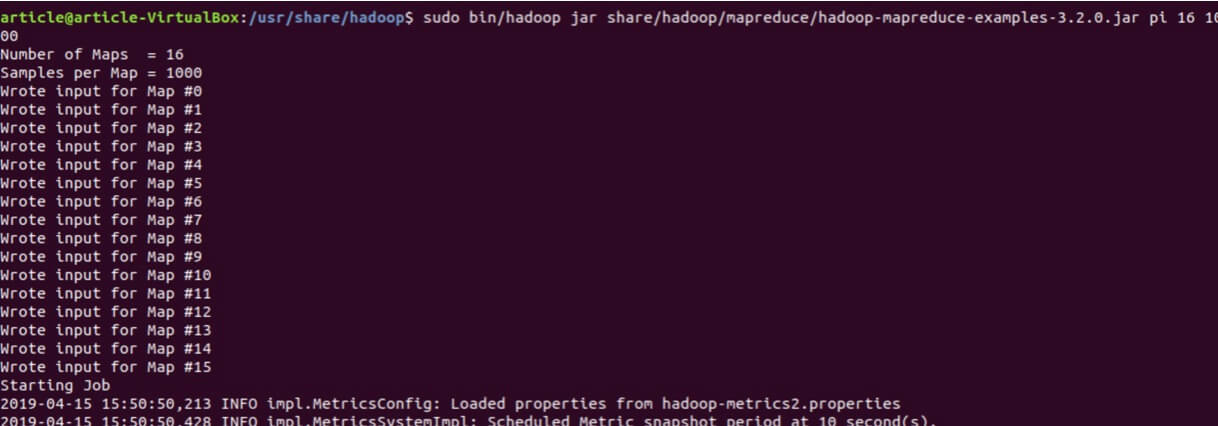
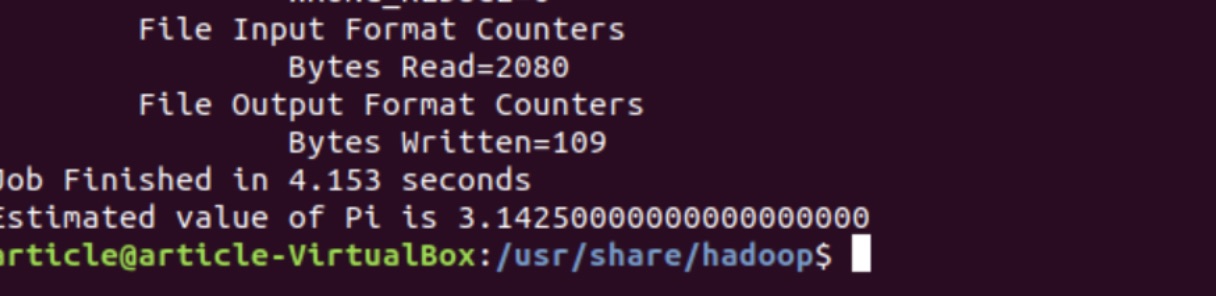
- Next, we will try running a simple PI estimator program, which is included in the Hadoop Release. Try running the following command in the Terminal Window:
| sudo bin / hadoop jar share / hadoop / mapreduce / hadoop - mapreduce - examples - 3.2.0.jar pi 16 1000 |
The output should look similar to the following:
Pseudo-Distributed Operation
Another alternative to Standalone mode is Pseudo-Distributed mode. Under this mode, each Hadoop daemon / service runs a separate Java process.
-
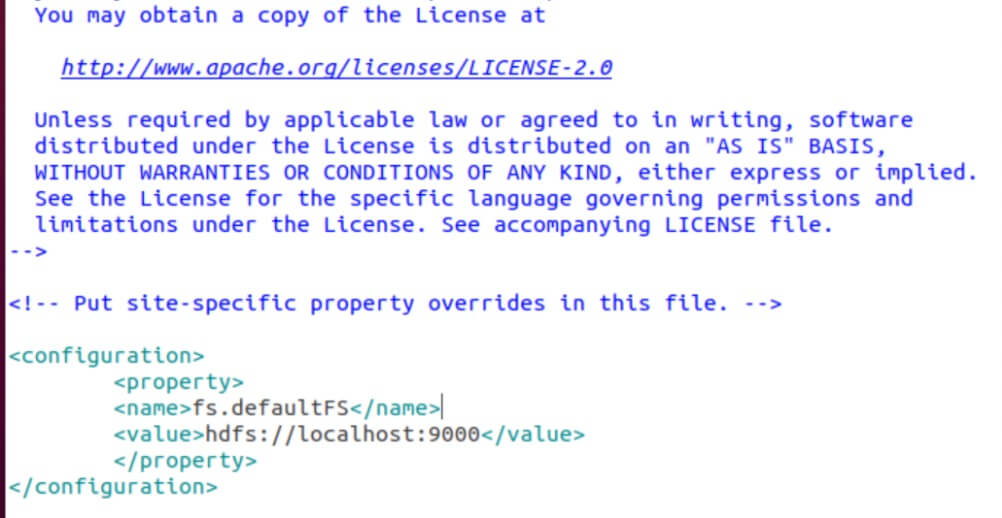
- Navigate to etc/hadoop/core-site.xml for editing and add the following xml code inside the 'configuration' tags in the core-site.xml file.
| fs . defaultFS hdfs : //localhost:9000 |
It should look like this:
-
- Navigate to etc/hadoop/hdfs-site.xml for editing and add the following xml code inside the 'configuration' tags in the hdfs-site.xml file.
-
- Check that you can ssh to the localhost without a passphrase. If you are prompted for a password, enter the following commands:
| $ ssh - keygen - t rsa - P '' - f ~ / . ssh / id _rsa $ cat ~ / . ssh / id_rsa . pub >> ~ / . ssh / authorized _keys $ chmod 0600 ~ / . ssh / authorized_keys |
Starting the NameNode and DataNodes
-
- The first thing you want to do before executing on the pseudo-distributed mode is to format the filesystem. Execute the following command in your HADOOP_HOME directory:
| $ bin / hdfs namenode - format |
-
- Next, start the NameNode and the DataNode daemon / services by entering the following command:
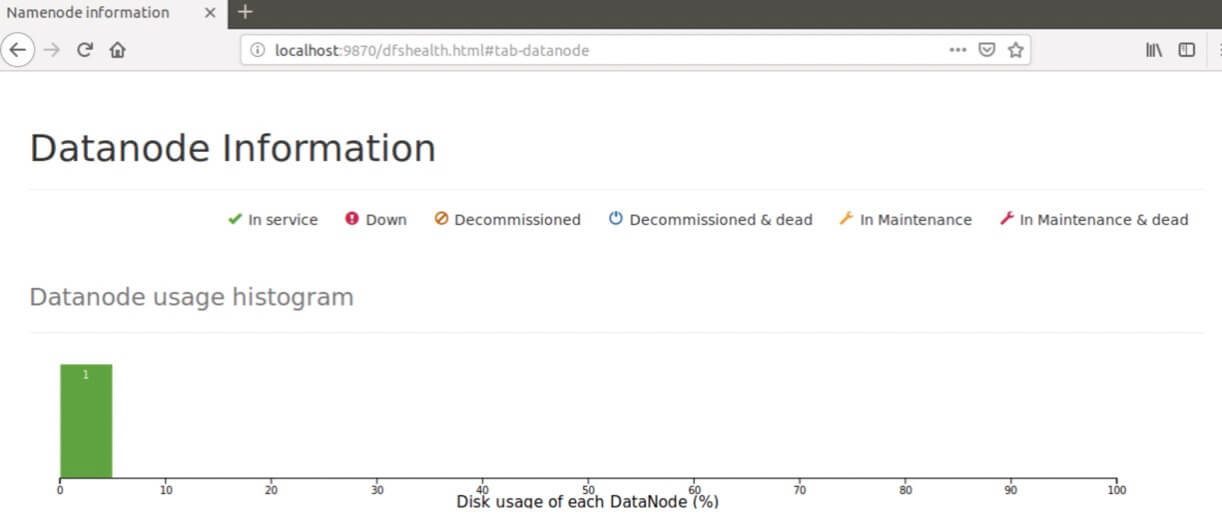
- After starting the instance, go to http://localhost:9870 on your favorite browser. The following screen should appear:

When navigating to the Datanode tab, we see that we have 1 node.
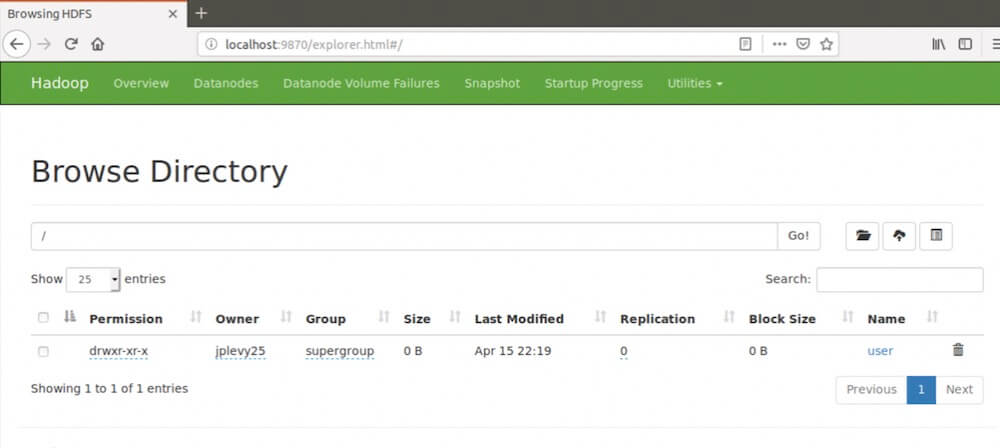
In addition to the nodes, you can see "Browse Directory."
In Part 2 of this Article, I will dive deeper into the functionality of the NameNode and DataNode(s) as well as show how to ingest data into the Hadoop ecosystem.
References:
- https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Installing_Software
- Sams Teach Yourself Hadoop in 24 Hours by Jeffrey Aven, 2017 at Amazon
Questions?
Thanks for reading! We hope you found this blog post to be useful. Do let us know if you have any questions or topic ideas related to BI, analytics, the cloud, machine learning, SQL Server, (Star Wars), or anything else of the like that you'd like us to write about. Simply leave us a comment below, and we'll see what we can do!
Keep your data analytics sharp by subscribing to our mailing list
Get fresh Key2 content around Business Intelligence, Data Warehousing, Analytics, and more delivered right to your inbox!
Key2 Consulting is a data warehousing and business intelligence company located in Atlanta, Georgia. We create and deliver custom data warehouse solutions, business intelligence solutions, and custom applications.
How to Install Hadoop on Windows 10 Using Vmware
Source: https://key2consulting.com/install-hadoop-on-linux-virtual-machine-on-windows-10/